Bestpracticesobservability
Los 3+1 Pilares de la Telemetría: Metrics, Logs y Traces más Profiling

Cuál es la diferencia entre Observabilidad y Monitorización
La monitorización es una práctica de recopilación de datos sobre el rendimiento y el comportamiento del sistema. Es una parte crucial de la observabilidad, pero no proporciona el mismo nivel de conocimiento que nos puede proporcionar la Observabilidad. La observabilidad va más allá de la simple recopilación de datos, ya que permite hacer preguntas y explorar las causas raíz de los problemas.
Qué es Observabilidad
La observabilidad es la capacidad de obtener información sobre el funcionamiento interno de un sistema mediante el análisis de sus resultados. Esta información es crucial para solucionar problemas, optimizar el rendimiento y mejorar la seguridad. En términos más simples, la observabilidad te permite comprender por qué un sistema se comporta de cierta manera.
La observabilidad es la forma de medir “cómo de bien” se pueden inferir los estados internos de un sistema a partir del conocimiento de sus resultados externos. A menudo se confunde con el monitoreo, pero la observabilidad va un paso más allá al identificar problemas en un sistema y determinar por qué ocurren. Proviene de la teoría de control y se ha convertido en fundamental en la ingeniería de software, especialmente con el auge de sistemas complejos, distribuidos y microservicios. La observabilidad recopila datos de métricas, registros (logs) y trazas, los tres pilares, para ofrecer una visión completa del estado y rendimiento de un sistema.

Cuándo deberíamos usar logs vs. metrics vs. traces
Al decidir cómo instrumentar tus sistemas y qué tipos de datos de telemetría utilizar, es importante considerar tu estrategia general de observabilidad y los casos de uso que deseas habilitar. Luego, puedes aprovechar los diferentes tipos de datos en consecuencia. Dado que cada uno tiene fortalezas y debilidades, lo ideal suele ser utilizar una combinación de métricas, trazas y registros (logs), asignando cada tipo de telemetría a sus beneficios específicos y utilizando otros para compensar sus limitaciones. Aunque los detalles pueden variar significativamente y no hay una única respuesta “correcta”, aquí tienes algunas pautas que pueden ayudarte a determinar cuál es la mejor opción para cada caso de uso:
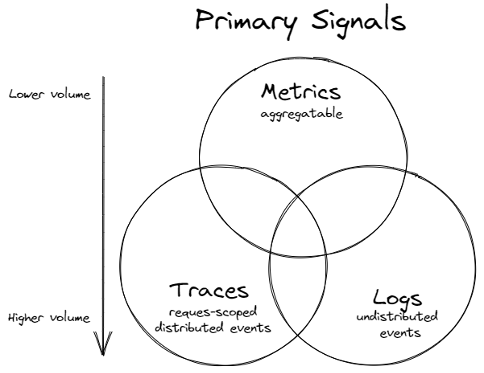
- Usa métricas para KPI de referencia frecuente o como entrada para alertas, donde el rendimiento es importante y los patrones de acceso se conocen de antemano.
- Usa métricas para el seguimiento de mediciones durante períodos prolongados, como meses o años.
- Usa trazas en casos donde comprender la relación entre servicios u operaciones dependientes sea especialmente valioso.
- Usa logs o trazas en los casos donde se requerian análisis ad-hoc o troubleshooting en campos de alta cardinalidad.
- Usa logs en los casos donde necesitemos información de interés en ese caso, como error messages o stack traces.
Logs, metrics y trazas son la base de cualquier sistema observable. Estos 3 pilares nos dan distintas perspectivas del comportamiento del sistema y del performance, y usándose juntas, nos dan completa visibilidad. Entender cómo estos tres pilares trabajan conjuntamente es una buena estrategia de observabilidad. Cada pilar nos da información de forma distinta, y cuando se usan conjuntamente se puede ver el conjunto del sistema.
Qué son los logs?
Logs son el dato más detallado de observabilidad, capturando eventos de forma eventual en tu sistema. Pueden ser de texto plano, estructurado o binario, cada uno para distintos casos de uso:
- Logs en texto plano son simples y legibles.
-
Logs estructurados son formateados, pudiendo ser parseados de manera sencilla y analizados de forma automática, e.g.
[15/Nov/2021:04:47:53 -0500] 192.168.56.87 [31221] [/home/menu] [2335] ERROR: record id=23434 not found in tablevs
{ "hostName": "192.168.0.1", "pid": "31221", "path": "/home/menu," "error_number": 2335 "message": "ERROR: record id=23434 not found in table." } - Logs en Binario son más eficiente pero necesitan herramientas especiales para poder ser interpretados.
Rol de Logs
Los Logs tienen varios roles clave en la monitorizacion y la gestión de los sistems. Son esenciales para:
Monitorización en Tiempo Real: Visibilidad inmediata de los eventos de sistema. Troubleshooting: Información detallada para diagnosticar problemas. Compliance: Seguimiento de cambios y acceso para cumplir con los requisitos. Análisis de Negocio: Información útil a partir de las operaciones del sistema.

Reto de los Log
Independientemente de su importancia, los logs son un reto. El volumen de logs puede ser abrumador, llevando a costes elevados en almacenamiento y problemas de performance. El procesamiento y análisis de estos datos necesitan una solución robusta:
Big data: El manejo de grandes cantidades de datos consume muchos recursos. Performance: el logging puede llegar a impactar el performance del sistema. Coste: el almacenamiento y la gestión de datos de log es cara.
El tratamiento de los eventos de logging como un procesamiento en stream puede ayudar con algunos de estos retos, con herramientas como Kafka …
Qué son las métricas
Definiendo métricas
Las métricas son representadas como series temporales. Han evolucionado hasta tener etiquetas que añaden dimensiones y contexto a un simple dato puntual. Por ejemplo, las métricas de CPU pueden tener etiquetas por servidor, aplicación o region. Esto ha hecho que las métricas de observabilidad sean una herramienta robusta de monitoreo y análisis de tendencias en tiempo real.
Ventajas de las métricas
Tableros: Crear visualizaciones que te dan una vista rápida de la salud del sistema para que puedas verificar rápidamente.
Alertas: Impulsar sistemas de notificación en tiempo real para avisarte cuando algo va mal.
Transformaciones matemáticas: Puedes calcular promedios o realizar detección de anomalías para profundizar en el comportamiento del sistema y las tendencias de rendimiento.
Desventajas de las Métricas
Pero las métricas no están exentas de sus limitaciones:
Alta cardinalidad: Cuando hay muchas combinaciones únicas de etiquetas, puede ralentizar el rendimiento y dificultar el análisis de datos.
Vista resumida: Las métricas te dan una vista resumida del rendimiento del sistema, que puede no tener suficiente detalle para diagnósticos profundos.
Por lo tanto, no son ideales para identificar problemas específicos sin contexto adicional de logs o trazas.
Qué son las trazas
Explorando Trazas
Las trazas siguen las request a medida que fluyen a través de un sistema, capturando eventos relacionados. Este nivel de detalle es clave para entender cómo interactúan las diferentes partes de tu sistema y dónde están los cuellos de botella. La trazabilidad te muestra el recorrido de una request desde el inicio hasta el final y dónde las cosas salen mal en el camino.
Beneficios de las Trazas
Optimizar el flujo de request para cumplir con los niveles de servicio ( SLA, SLO ).
Diagnósticos y soluciones de problemas de rendimiento más fáciles = desarrollo y operaciones más eficientes.
Desafíos de las Trazas
La trazabilidad puede ser complicada y pesada en recursos. A menudo requiere:
Cambios manuales en el código: Instrumentalizar el sistema.
Limitaciones de cobertura en el backend: Las trazas no cubren todos los servicios de backend.
Pero están surgiendo service mesh que están resolviendo estos desafíos al hacer que el trazado sea más fácil y completo.
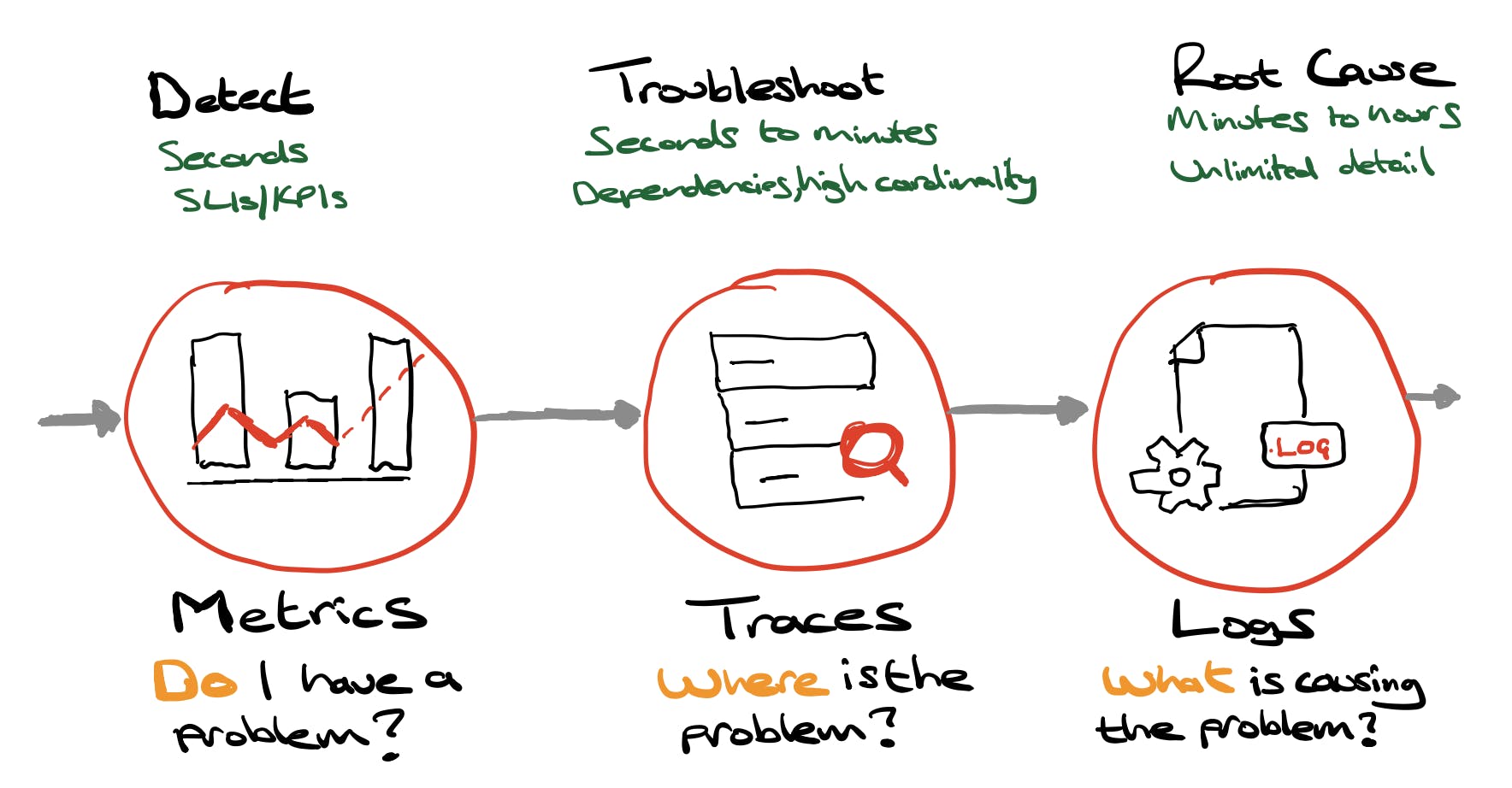
Cómo las Métricas, logs y Trazas Trabajan Juntas
La combinación de métricas, logs y trazas crea un entorno para la supervisión avanzada y la resolución de problemas en entornos de IT. Cada uno de estos tres pilares proporciona información única, pero juntos te dan una vista completa de los sistemas y aplicaciones.
Observabilidad Las métricas son datos numéricos que miden las operaciones en un sistema, como tiempos de respuesta, uso de recursos y tasas de error.
Los logs son registros detallados de lo que sucede en el sistema, proporcionando contexto y detalles sobre operaciones y eventos.
Las trazas te permiten seguir el recorrido de una request o transacción específica a través de diferentes componentes y servicios.
Cuando estas piezas están conectadas,se pueden hacer referencias cruzadas de información rápidamente.
Por ejemplo, un aumento en una métrica puede llevar a un desarrollador a mirar los logs en el momento exacto del aumento para ver lo que estaba sucediendo en el sistema. Si los logs muestran un error o un evento inusual, las trazas pueden usarse para seguir el camino de la solicitud afectada para ver qué servicios o componentes estaban involucrados y cómo interactuaron.
Este uso de datos no solo acelera el proceso de resolución de problemas, sino que también te brinda una mejor comprensión del comportamiento del sistema en operaciones del mundo real.
La trazabilidad distribuida es el como el anillo único que ata a los otros anillo, o en nuestro caso “el relato” de observabilidad. Nos da contexto y datos asignado un identificador único a cada petición, las trazas nos permitirán seguir el viaje de esa request a través de los servicios, revelando el flujo de la aplicación, los cuellos de botella de rendimiento y los errores.
Las trazas nos permiten una visión unificada del comportamiento de sistema, conectado eventos dispares en una narrativa coherente.
Links:
https://read.srepath.com/p/intro-to-logs-metrics-and-tracing
https://edgedelta.com/company/blog/tracing-vs-logging-differences-with-examples#:~:text=Tracing%20records%20the%20journey%20of,when%20tracing%20is%20widely%20used.
https://www.honeycomb.io/blog/understanding-logs-vs-traces